Fire-and-Forget Is a Lie: Why Your Async Jobs Need a Persistence Safety Net
May 02, 2026 • ArchyPress

We built an AI generation engine that streams results in real-time via WebSocket. Beautiful UX. Progressive loading. The user watches posts materialize word by word. There was just one problem: if they closed the tab, everything vanished.
The Architecture That Almost Worked
The design was elegant on paper. A server function kicks off AI generation, streams progress via Supabase Realtime, and the client renders results as they arrive. The flow:
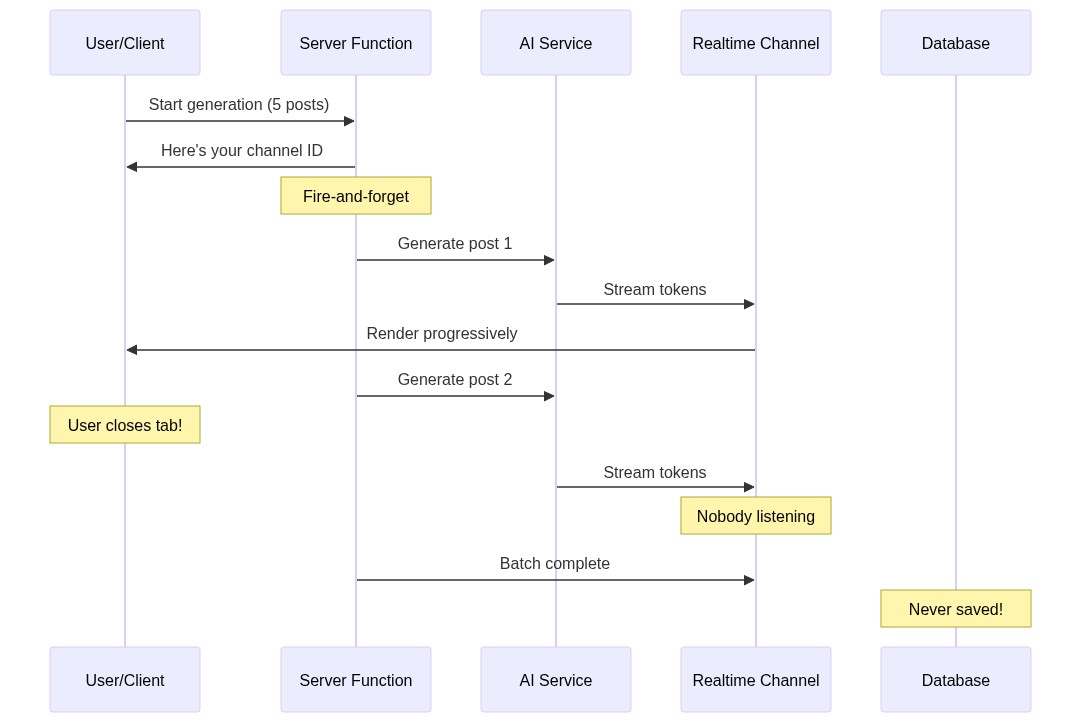
The killer detail: the save-to-database step only happened in the client's onBatchComplete callback. The server generated content, broadcast it into the void, and moved on. If the user wasn't there to catch it —
poof.
Why Developers Build It This Way
This pattern emerges naturally when you're iterating fast:
Version 1: Synchronous — user waits, server generates, returns result. Simple.
Version 2: Stream results for better UX — server pushes tokens via WebSocket, client renders in real-time. The client already has the data in memory, so it saves at the end.
Version 3: Fire-and-forget for performance — server function returns immediately, async generation happens in the background. Client subscribes to the channel.
Each step is a reasonable evolution. But by version 3, you've introduced a critical assumption: the client will be there to persist the results. That assumption was fine in version 1 (synchronous, user can't leave) and version 2 (streaming, user is watching). In version 3? It's a bug.
The Failure Mode in Practice
Here's what actually happens to users:
Tab close during generation
User starts generation, goes to make coffee, comes back to a blank wizard. The AI cost was incurred but the content is gone.
Mobile background kill
Mobile browser puts the tab in background, OS kills the WebSocket. Generation completes server-side with no listener.
Network blip
Intermittent disconnect drops the Realtime subscription. Some posts arrive, some don't. Partial state saved.
Multi-tab confusion
User opens a new campaign in another tab. First tab's channel gets confused or disconnected.
The Fix: Incremental Server-Side Persistence
The principle is simple: the server must persist results independently of the client. The client is a convenience layer for real-time feedback, not the source of truth.

The key changes:
After each post finishes generation, the server writes the current batch state to the database
The write is incremental — it updates the existing draft record with all completed posts so far
A final write at batch completion marks generation as 'complete'
The client save becomes a no-op optimization (deduplicate, don't create)
The Persistence Pattern
// Server-side: after each post completes
async function persistBatchProgress(batch) {
const completedPosts = batch.posts
.filter(job => job.status === 'complete' || job.caption)
.map(job => ({
network: job.network,
caption: job.caption,
imageUrl: job.imageUrl,
videoUrl: job.videoUrl,
status: job.status === 'complete' ? 'approved' : job.status,
}));
// Merge into existing draft (preserve wizard settings)
const existing = await db.getDraftState(batch.campaignId);
await db.updateDraftState(batch.campaignId, {
...existing,
posts: completedPosts,
generationStatus: allDone ? 'complete' : 'generating',
});
}
What About Write Amplification?
"But won't writing to the database after every post be expensive?" Fair question. Let's do the math:
A typical batch has 5–15 posts
Each persist is a single UPDATE on one row (the campaign record)
The payload is a JSON column — one write, no joins
At 15 writes over 2–3 minutes of generation, that's ~5 writes/minute
Your database handles millions of writes/minute. This is noise.
The cost of persistence is negligible. The cost of losing 3 minutes of AI generation (and the API credits that went with it) is not.
The Client-Side Complement
With server-side persistence, the client's role simplifies:
Real-time streaming (UX only)
The client subscribes to the Realtime channel for live progressive rendering. If it disconnects, no data is lost.
Resume from persisted state
When the user returns, the client loads the draft from the database. Completed posts appear instantly. In-progress ones show as 'generating'.
Client save becomes optional
The client's batch-complete handler can still save (for immediate UI consistency) but it's no longer the only save point.
The Broader Principle
If your server does expensive work, persist the results on the server. Don't delegate persistence to the consumer of a real-time channel.
This applies beyond AI generation:
File processing pipelines that report progress via WebSocket — write intermediate results to object storage
Long-running data exports that stream rows to the client — write the export file server-side regardless
Payment processing that broadcasts status updates — the payment state machine lives in the database, not in a client subscription
Build/CI systems that stream logs — logs are persisted independently of whether anyone is watching
The pattern: real-time channels are for notification, not persistence. They complement durable storage; they don't replace it.
Lessons Learned
Fire-and-forget is fine for the function call. It's not fine for the results.
Any time you add 'fire-and-forget' to a pipeline, ask: 'who persists the output?'
If the answer is 'the client, in a callback' — you have a data loss bug for any disconnection scenario.
The fix is almost always cheap: one extra database write per significant progress step.
Want resilient AI generation?
ArchySocial's generation engine persists every completed post server-side, so you can close your laptop mid-generation and come back to finished content.